The Gemma 4 Family
| Model | Type | Modalities | 4-bit RAM | 24GB Mac? |
|---|---|---|---|---|
| E2B | Dense (2.3B eff.) | Text, Image, Audio | 4 GB | 95 tok/s |
| E4B | Dense (4.5B eff.) | Text, Image, Audio | 5.5 GB | 57 tok/s |
| 26B-A4B | MoE (4B active) | Text, Image | 16-18 GB | ~2 tok/s |
| 31B | Dense (31B) | Text, Image | 17-20 GB | Won't fit |
Speed Benchmarks
Tested with identical coding/translation prompts, 512 max tokens, Gemma 4 default parameters (temp=1.0, top_p=0.95, top_k=64).
Audio ASR: 3 Languages
Tested via Ollama's OpenAI-compatible endpoint (/v1/chat/completions with input_audio). E2B and E4B only — 26B/31B don't support audio.
English ASR
Ground truth: "Hello, I am an artificial intelligence model. Today we will test speech recognition in English. Technology is evolving rapidly and language models are becoming more capable every day."
"Hello. I am an artificial intelligence model. Today we will test speech recognition in English. Technology is evolving rapidly and language models are becoming more capable every day."
Perfect transcription.
"Hello today's speech recognition in English language models technology is evolving rapidly language models are becoming more capable every day"
Garbled — missing words, no punctuation.
French ASR
Ground truth: "Tous les êtres humains naissent libres et égaux en dignité et en droits. Ils sont doués de raison et de conscience et doivent agir les uns envers les autres dans un esprit de fraternité."
"Tous les êtres humains naissent libres et égaux en dignité et en droits. Ils sont doués de raison et de conscience et doivent agir les uns envers les autres dans un esprit de fraternité."
Perfect transcription with accents.
"ils doivent raison et de conscience et droits humains libres et d'esprit de fraternité"
Fragmented, missing most of the text.
Arabic ASR
Ground truth: "مرحباً، أنا نموذج ذكاء اصطناعي. اليوم سنختبر التعرف على الكلام باللغة العربية."
"مرحبًا، أنا نموذج ذكاء اصطناعي. اليوم سنختبر التعرف على الكلام باللغة العربية. التكنولوجيا تتطور بسرعة والنماذج اللغوية أصبحت أكثر كفاءة."
Perfect Arabic transcription.
"اكثر ركفاء نماذج لغويه اصبحت عبري علم الكلام..."
Garbled — wrong words, disordered.
Speech Translation (E4B)
French → English
"All human beings are born free and equal in dignity and rights. They are endowed with reason and conscience, and must act toward one another in a spirit of fraternity."
Arabic → English
"Hello, I am an artificial intelligence model. Today we will test speech recognition in the Arabic language. Technology is developing quickly, and language models have become more efficient."
Image Understanding
Tested via Ollama /api/chat endpoint. All 4 models support vision.
Test 1: Landmark Identification

Prompt: "What country and city? Name the landmark."
"Country: Thailand. City: Bangkok. Landmark: Wat Phra Kaew (Temple of the Emerald Buddha) within the Grand Palace complex."
"Country: Thailand. City: Bangkok. Landmark: Grand Palace complex."
Correct but less specific — didn't name Wat Phra Kaew.
Test 2: AI-Generated Image + Japanese OCR
AI-Generated with nano-banana / Gemini

Prompt: "Describe. Read any Japanese text. Is this AI-generated or real?"
"A photograph of a bustling, wet street scene in a commercial district in Japan, likely at dusk or night... Correctly identified: Shinjuku Ramen Dori (新宿ラーメン通り)"
"City: Tokyo, Shinjuku. Japanese text: 新宿ラーメン通り (Shinjuku Ramen Street), ひかりラーメン (Hikari Ramen)"
Both models correctly read Japanese kanji from an AI-generated image.
Test 3: Detailed Captioning

Prompt: "Detailed caption. Identify the city and any visible text."
"A magnificent seagull perches watchfully atop a sculpted pedestal, dominating the foreground. The backdrop is a rich study in contrasting architectural styles: to the right stands an immense, richly detailed classical facade..."
Full-Stack App Generation
Each model was asked to generate a complete React + Tailwind CSS Task Manager as a single HTML file.
E4B: Task Manager WORKS
52.1 tok/s · 2,073 tokens · 40.7s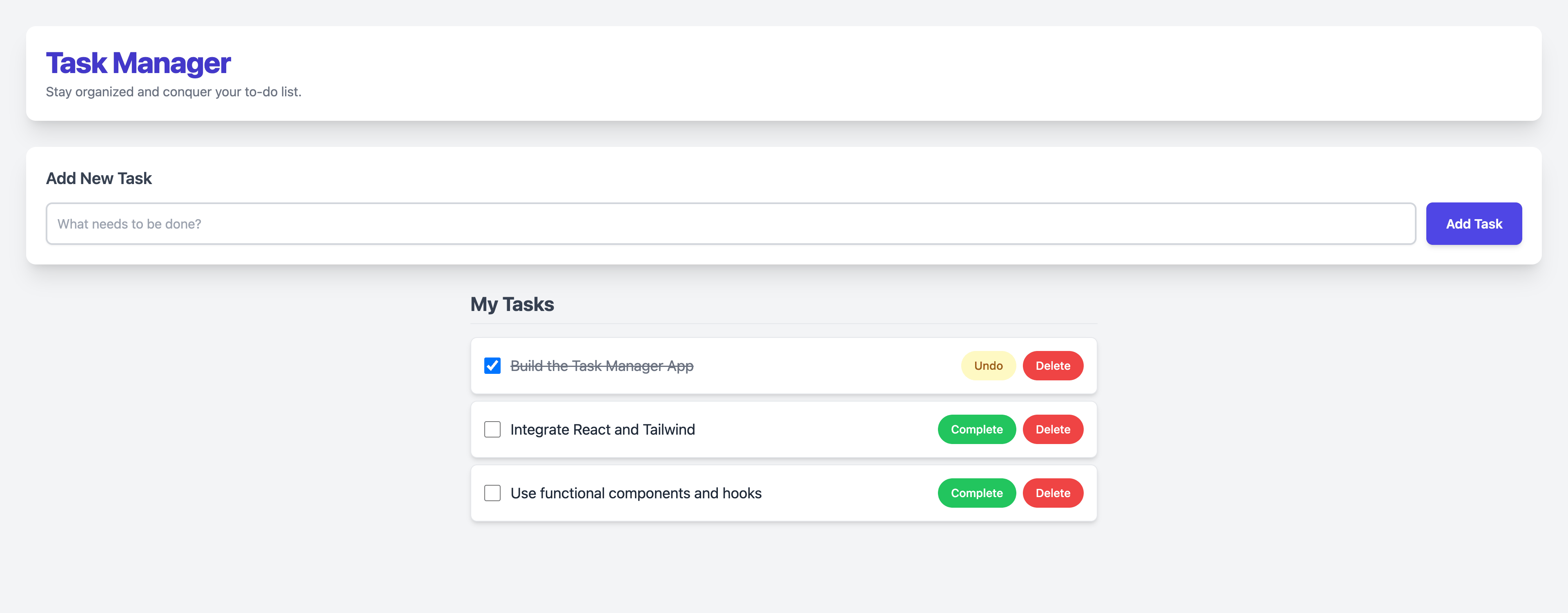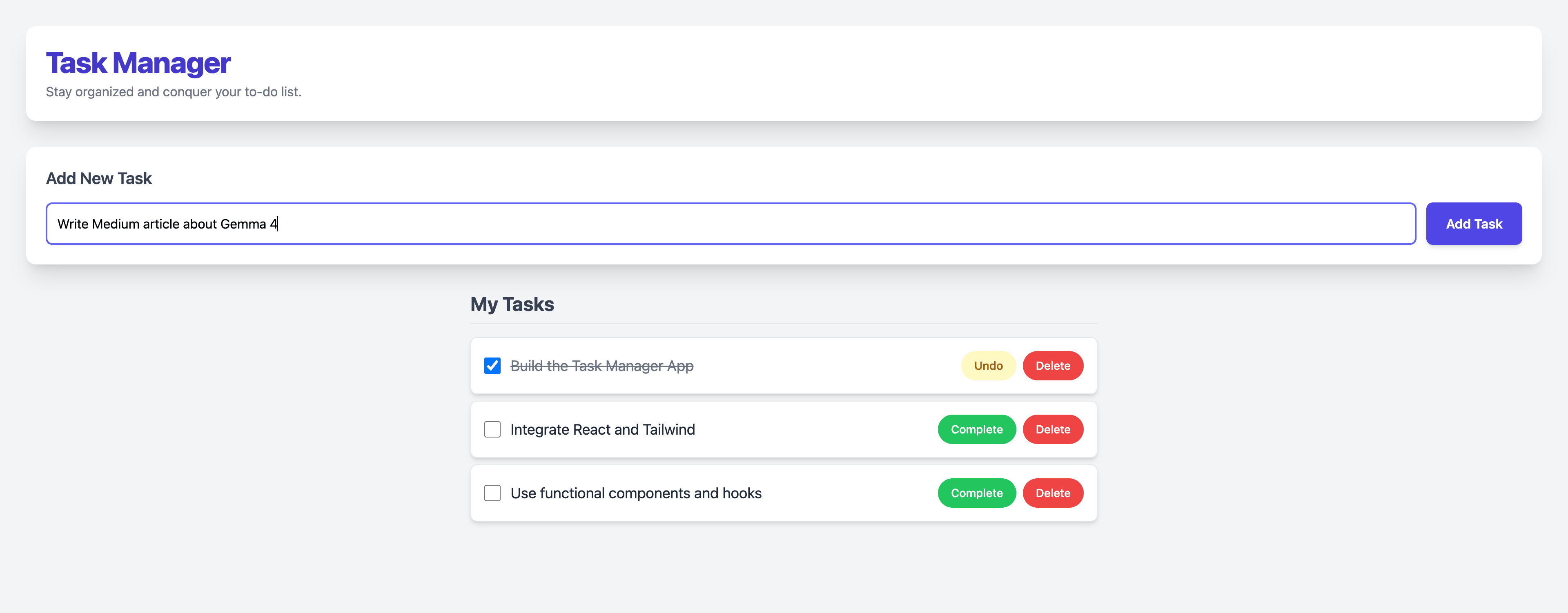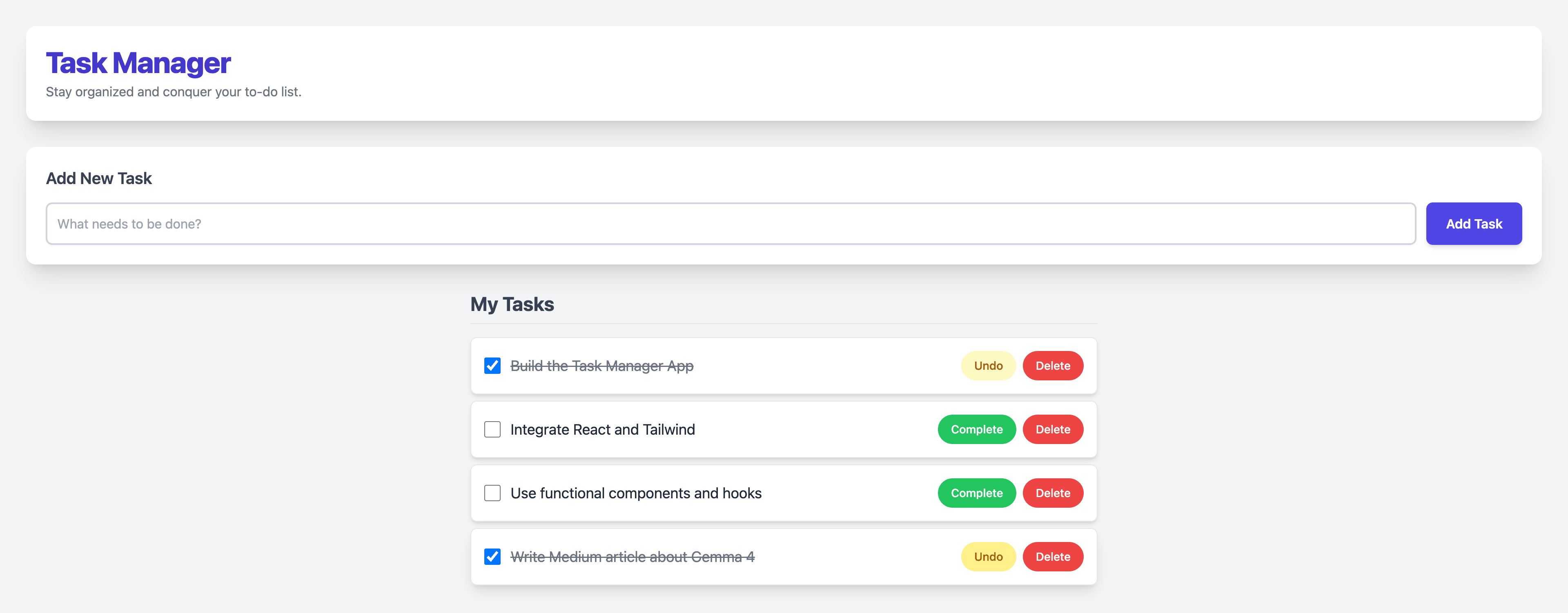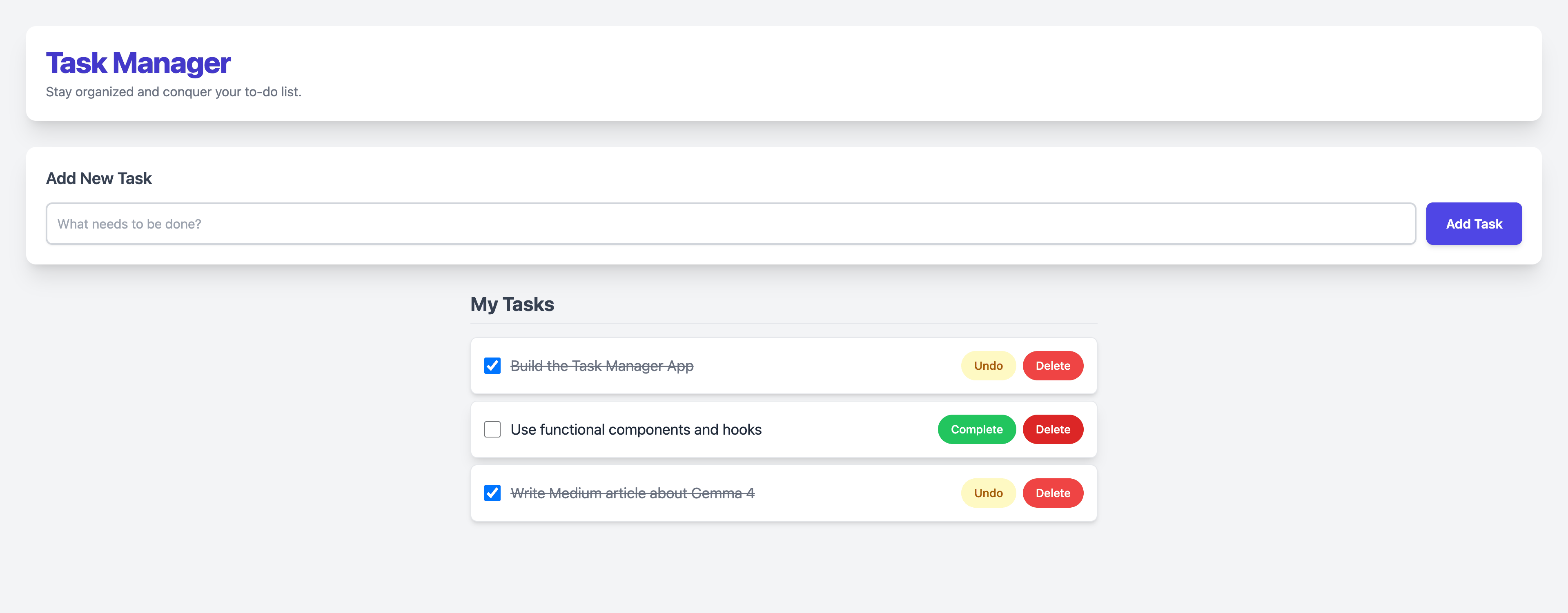
E2B: FAILED
Generated code fragments instead of a single HTML file. The 2B model couldn't follow the "single file" constraint.
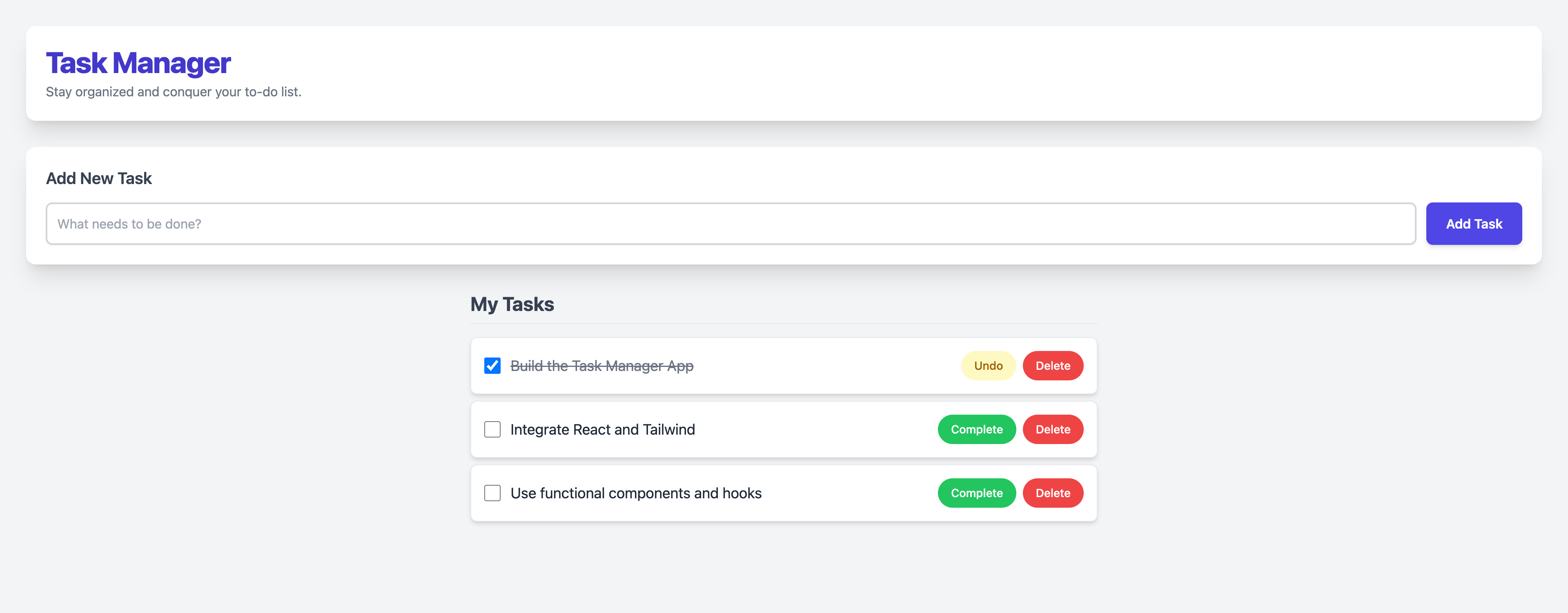
Step 1: Initial Load
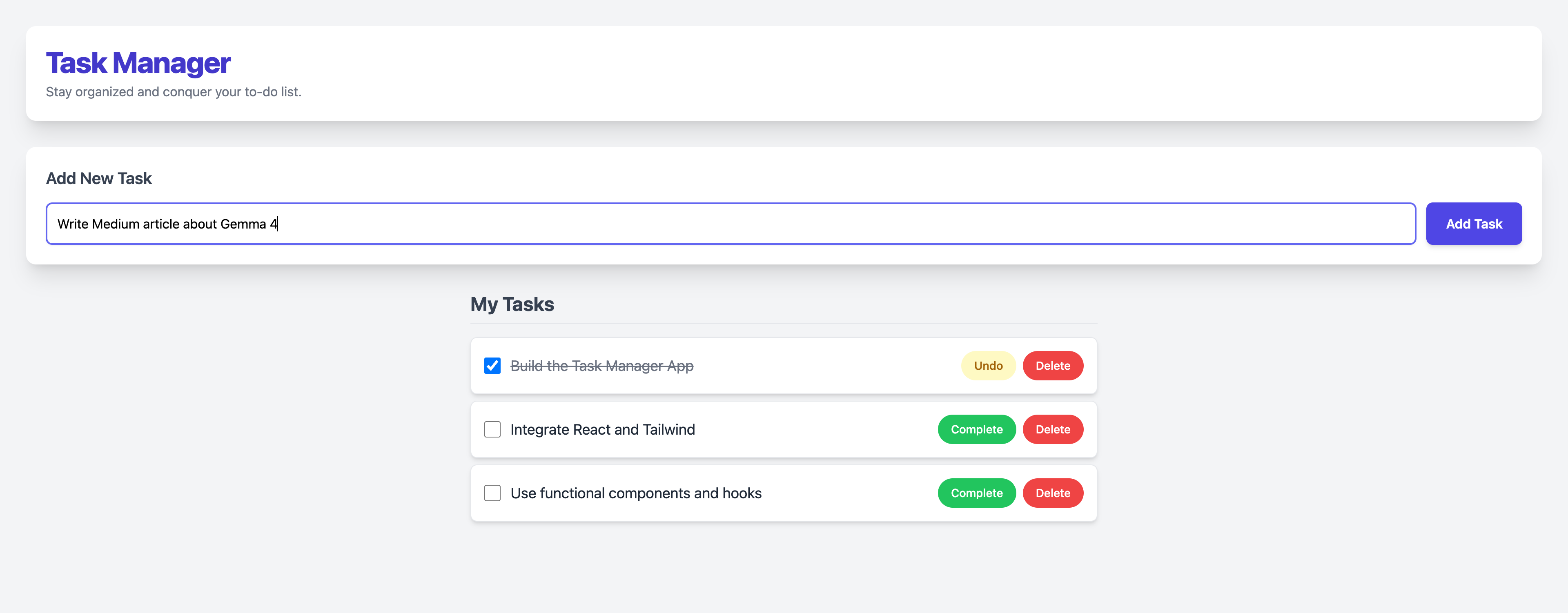
Step 2: Typing a Task
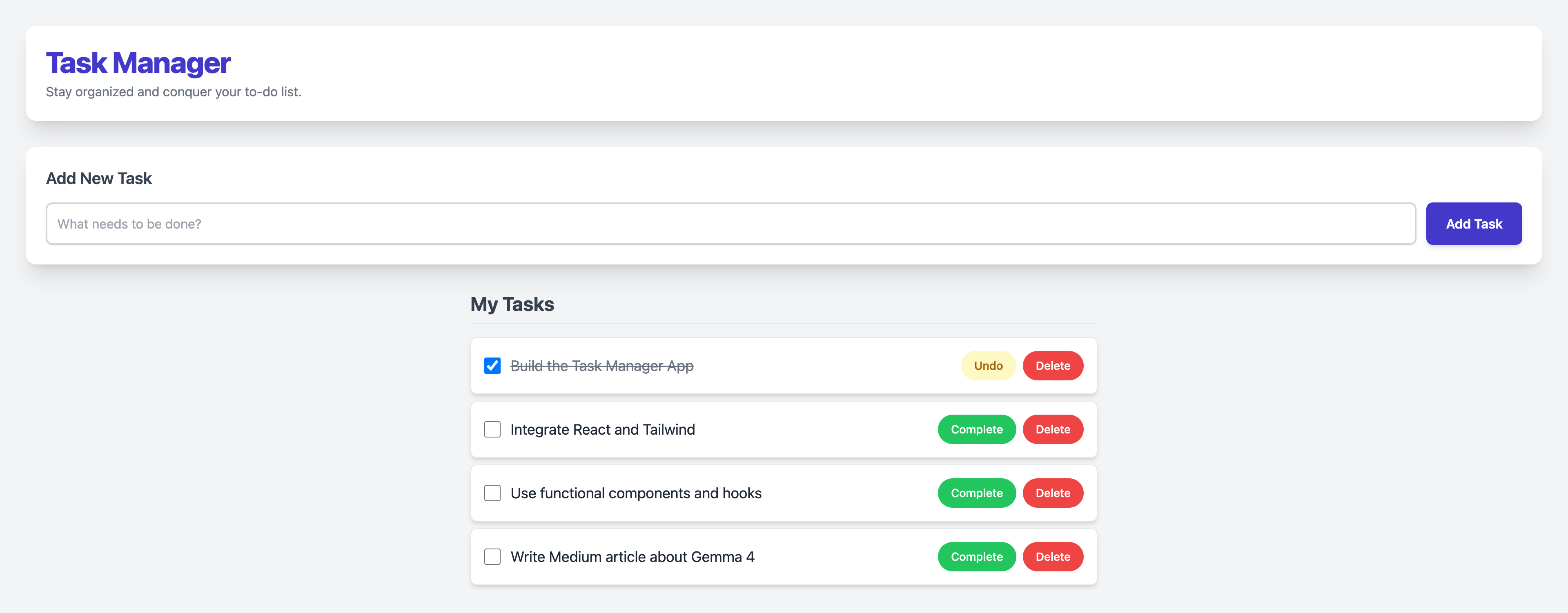
Step 3: Task Added
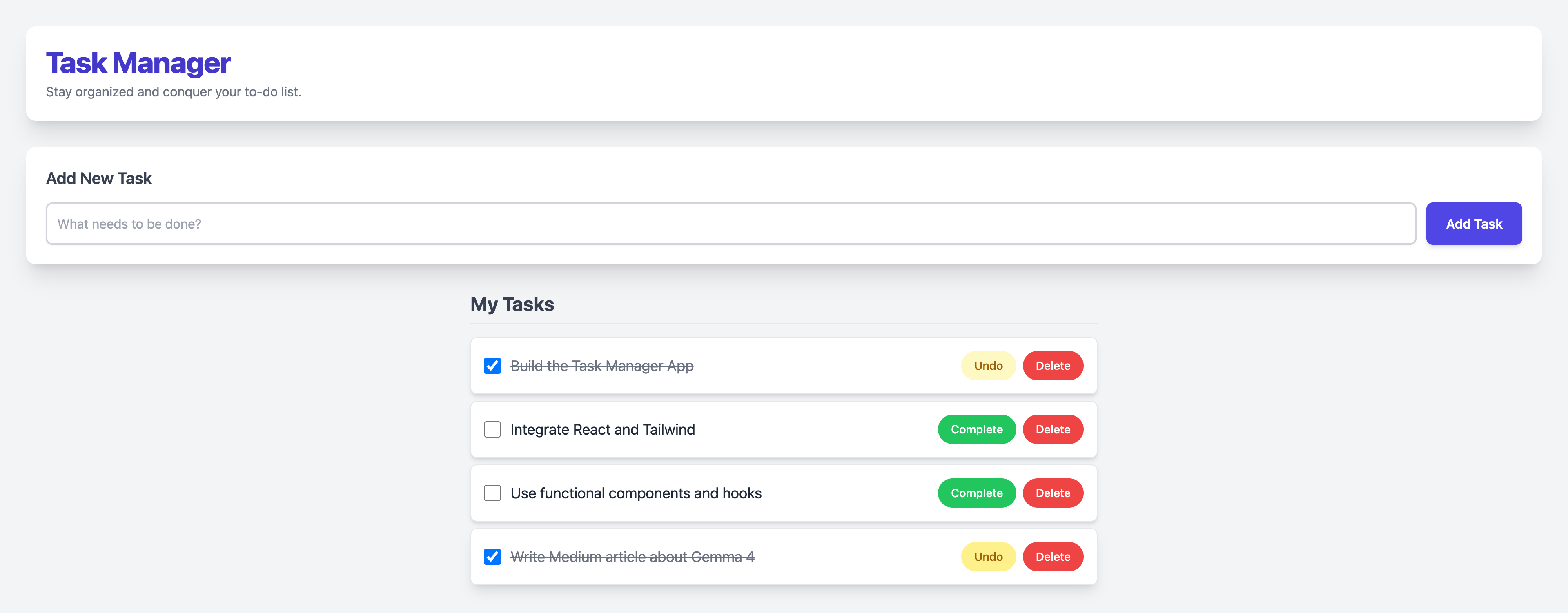
Step 4: Task Completed
Agentic Multi-Step Reasoning
6-step task: design a blog platform with DB schema, SQLAlchemy models, FastAPI endpoints, React frontend, Dockerfile, and deployment checklist.
E2B
6/6 steps · 7 code blocks · Python, TSX, Dockerfile
9,258 chars · 78 tok/s · 43s
E4B
6/6 steps · 5 code blocks · Python, TSX, Dockerfile
14,562 chars · 49 tok/s · 85s
Coding: Compile & Run
Generated Python scripts and executed them. Both pass all 4 tests.
| Script | E2B | E4B |
|---|---|---|
| Fibonacci (first 20) | PASS | PASS |
| Sieve of Eratosthenes | PASS | PASS |
| JSON nested processor | PASS | PASS |
| HTTP request (urllib) | PASS | PASS |
| React+Tailwind single file | FAIL | PASS |
Why 26B Fails on 24GB
From community testing (r/LocalLLaMA): Gemma 4 has a KV cache memory problem.
- 31B at full 262K context: ~22GB just for KV cache (on top of model)
- People with 64GB RAM + 24GB VRAM are getting OOM errors
- Google did NOT adopt KV-reducing techniques (Lightning Attention, Mamba-2) that Qwen 3.5 uses
- llama.cpp sliding window implementation may still have bugs
Workaround: --ctx-size 8192 --cache-type-k q4_0 --parallel 1
Official Benchmarks
Final Verdict
E4B
The Sweet Spot · 57 tok/s
- ✅ Perfect ASR in English, French, Arabic
- ✅ Generated working React+Tailwind app
- ✅ Reads Japanese text from AI images
- ✅ Names specific landmarks (Wat Phra Kaew)
- ✅ 6/6 agentic steps completed
- ✅ Speech translation FR/AR → EN
8.5 / 10
E2B
Speed Demon · 95 tok/s
- ✅ Fastest model (95 tok/s)
- ✅ 3.6 GB memory (MLX)
- ✅ Coding scripts compile & run
- ❌ Garbled audio transcription
- ❌ Failed single-file HTML generation
- ✅ Reads Japanese OCR (basic)
7 / 10
For 24GB MacBook: ollama run gemma4:e4b
It's fast, it's smart, it's free, and it handles text + image + audio in 140+ languages.